Treehouse Dataflow Toolkit (TDT): Fully Automated, Cloud-native Data Transfer from Mainframe Data Sources to Analytics/ML/AI-friendly Targets
TDT provides an easy and fast approach that enables rapid and comprehensive data transfer from Kafka pipelines to Amazon Redshift, Snowflake, Amazon Athena/S3, Amazon S3 Express One Zone, and Amazon Aurora PostgreSQL–AI-ready, with all target resources automatically created.
Treehouse Dataflow Toolkit (TDT) is a set of Lambda-based microservices that assure highly-available, auto-scalable, and event-driven data transfers to your data science teams’ favorite analytics frameworks.
Customers either already have, or are in the process of acquiring, software tools that replicate their mainframe data into Kafka pipelines (i.e., Amazon MSK, Confluent, etc.). Our new and innovative offering, TDT, provides the turnkey solution for getting this data from Kafka into advanced Analytics/AI/ML-friendly targets, such as Amazon Redshift, Snowflake, Amazon Athena/S3, Amazon S3 Express One Zone Buckets, as well as Amazon Aurora PostgreSQL, all the while adhering to AWS’s and Snowflake’s recommended best practices for massive data loading, thus assuring shortest and surest loads.
How does TDT Work?
When a mainframe data replication tool (provided by one of Treehouse’s partners) publishes both bulk-load and CDC data to a reliable and scalable framework like Kafka, it sets the stage for TDT to feed legacy data from Kafka to any number of ETL tools, target datastores, and data analytics packages (some of which may not even have been invented yet!).
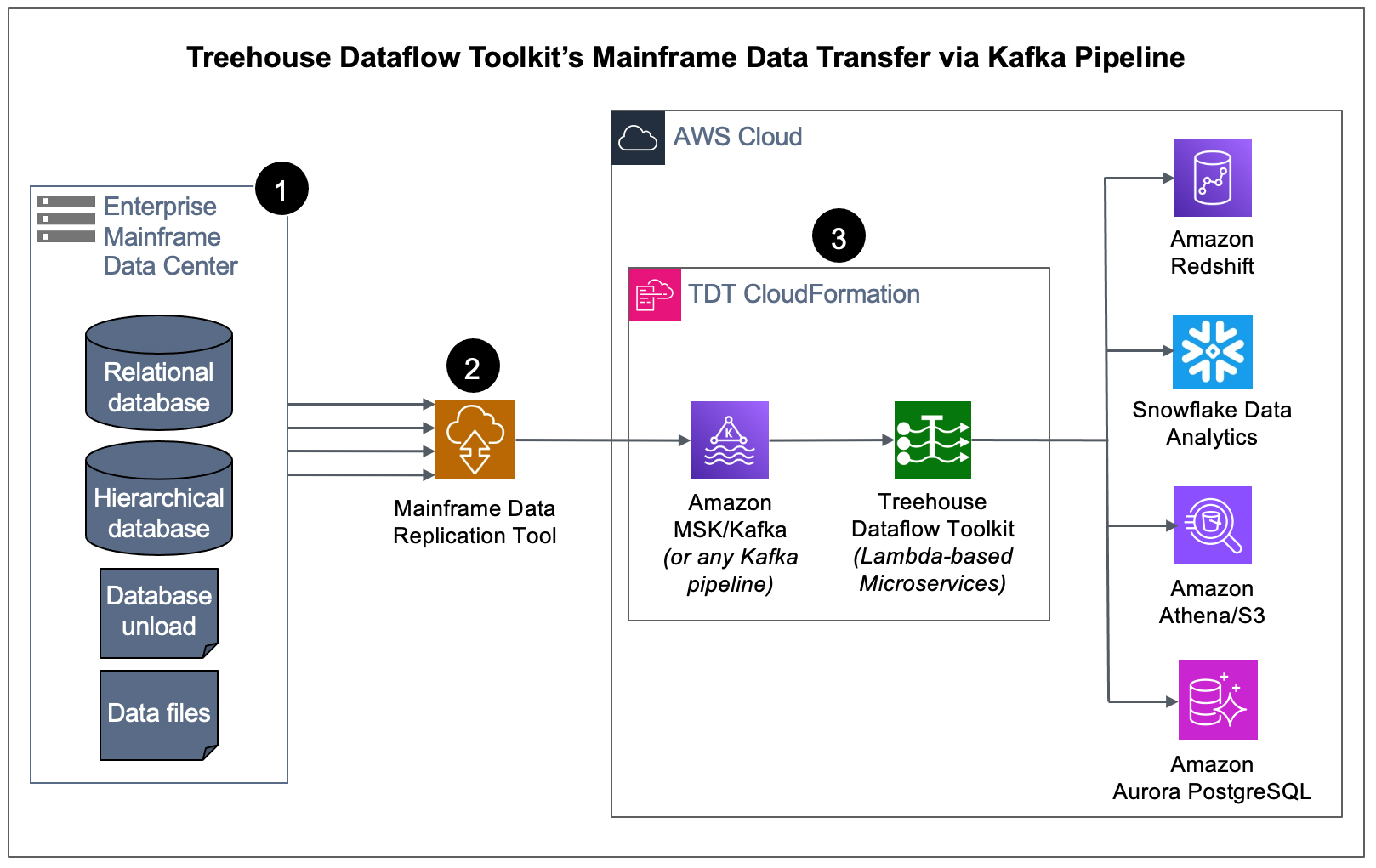
- We start at the source – the mainframe – where an agent (with a very small footprint) extracts data (in the context of either bulk-load or CDC processing).
- The raw data is securely passed from the mainframe by one of our partner’s data replication tools that transforms and publishes the data to a Kafka topic (in our example above, a topic in an Amazon MSK cluster).
- TDT microservices consume the data from MSK/Kafka and land it in S3 buckets, where TDT’s proprietary crawler technology is used to automatically prepare landing tables, views, and additional infrastructure for various analytics friendly targets. Then the mainframe data is loaded into Redshift, Snowflake, S3, or PostgreSQL (all the while adhering to AWS’s and Snowflake’s recommended “best practices” for massive data loading, thus assuring shortest and surest loads). The inherent reliability and scalability of the entire pipeline infrastructure assures near-real-time synchronization between mainframe sources and the target tables, even with huge bulk-loads or transaction-heavy CDC processing.
History is enterprise GOLD…
TDT not only keeps things up to date faster than any conceivable ODBC-based solution, but the “delta tables” into which it loads data also inherently retain the entire history of source data ever since mainframe-to-target synchronization began. So, for example, after TDT has been syncing a target table for 5 years, a data scientist now has 5 years’ worth of historical data to work with for trend analysis, predictive analytics, prescriptive analytics, ML, etc.
…but you also need the very latest data in near-real-time.
While TDT’s unique “delta-tables” approach offers comprehensive “history” for advanced analytics, the traditional need for up-to-the-second, current snapshots of mainframe datastores is also completely provided for. Adhering once again to target vendors’ “best practices”, self-materializing views are provided to work with current data, as well as in fully-structured views which provide the more traditional look and feel of a SQL database.
TDT leverages AWS CloudFormation for ease of implementation...
Treehouse provides highly-detailed CloudFormation Templates which automate and accelerate the process of installing and configuring the complete TDT application (including AWS Lambda functions and a number of other AWS resources) in your AWS account(s). The TDT CloudFormation Templates create stacks consisting of all principal framework components, along with related IAM policies and roles which are carefully engineered to comply with “best practices” (such as a “least privileges” approach to permissions).
The TDT CloudFormation Templates also optionally provide for automatic creation of a VPC, its subnets, and all required standard VPC-oriented resources, as well as optional creation of a source database cluster (consisting of either a sample database provided by Treehouse for a quick trial/POC, or your own database and data).
Simply put, TDT is a self-contained, automated solution that can eliminate months (or even years) of research and development time and costs, and allow customers to be up and running in minutes. TDT provides the turnkey solution for rapidly transferring data to advanced Analytics/ML/AI-friendly targets.
Treehouse Data Migration Professional Services on AWS: Treehouse Software's top-level AWS certified Cloud engineers specialize in enabling enterprises to tap into today’s advanced data analytics platforms, such as Amazon Redshift, Snowflake, and Amazon Athena/S3, where many ML/AI tools are available to generate vital insights from their data. |
Treehouse Dataflow Toolkit (TDT) is Copyright ©Treehouse Software, Inc. All rights reserved.
TDT-DIRECT AWS DMS Plugin for Snowflake
Download the AWS TDT Product Brief
Office Location
2605 Nicholson Road, Suite 1230
Sewickley, PA 15143
USA
Contact Us
General Email:
tsi@treehouse.com
Sales Department:
sales@treehouse.com
Support Center:
support@treehouse.com

Connect with Treehouse
![]()
![]()
![]()
![]()